|
I am sorry about messing things up in the first place. I went through the old chatlogs and from what i read the idea of having a newdev branch came up because of the wish for master to be more stable. I agree that merging newdev back into master and use tags is a good idea. About the questions: 2. I would like to keep using the centralised repo. I can’t publish my own since i don’t have a computer that runs 24/7 and setting up a repository requires a bit of extra learning and maintainance. I also think it would be hard to keep track of all the repositories and i don’t see any advantages so far. tsolife has a repository of its own and i think that makes sense because it is a partly seperated dev process. So i’d say at max one repository per project and not per developer. |
|
|
Proposal:
Planing:
|
|
|
Thanks azul for spending some time on sorting out what happened and your thoughts on where to go from here. I also agree that merging newdev back into master and using tags for releases is the way to go, and your 9 step proposal makes sense to me. Regarding the unresolved questions. As a server administrator, I can tell you what I would prefer and why. As part of the crabgrass development community, I have a better view into what is going on than your average sysadmin who might come to the project and want to download and install crabgrass. However, for the long-term health and viability of this project, I think we need to think like these people. When I am managing a server, with an instance of software installed, I want stability and clarity of what software is installed at what version. I am going to want to want to install a version of a piece of code, that I’ve evaluated as being the right one for the situation. Typically that is going to be the latest stable release version because this will give me the latest and greatest, but also the version that the developers have spent some time focusing their efforts on stabilization, documentation, upgrades and transitions, and an overall eye towards making their code the best possible thing it can be at the current state of development. Typically this involves a period of beta-testing, release candidates that the community has had a chance to deploy and weird corner-cases have been exposed and resolved. Version numbers may seem like arbitrary meta-data, but in the event of a problem in the code its very useful to be able to consult the version number of the code and make determinations from there about what to do (searching bug reports, reporting bugs, communicating with developers about issues, developers building up a knowledge-base about specific issues and their solutions, etc.). This is the long way of saying that version numbers, for a system administrator, are important, and when I am installing code for a ‘production’ site I do not want to be pulling from a repository to install, or to get the latest bug fixes, cherry-picking along the way. I want to install a stable, released version, and then not screw around with it (because people are expecting stability on their website) until the next stable released version is ready and I can upgrade it. That upgrade path I expect to be smooth because developers have spent some time testing that upgrade and working on transition scripts and resolving any problems. I also typically expect that a ‘stable’ released version will not be completely and totally abandoned by developers, and instead will get occasional water in the name of security fixes, and other non-intrusive stabilization fixes. Typically hard-core, tear the guts out and re-write significant chunks of code, adding major new features, etc. happen elsewhere, away from this stabilization effort. I do not want to periodically pull the latest git repository and make a decision about deploying production code based on the relative frequency of recent commits. I’m too busy managing servers, so I cannot keep up with development, as much as I would like and as far as I know the reason why there aren’t any commits in the last week is because everyone is working hard at fixing some major problem that is totally broken in the current HEAD. I will admit that occasionally I will be forced to grab some patch from unreleased code and apply it to a production install, typically when the problem is significant and a release is too far off, but that will be infrequent, the decision made explicitly, and it will be managed carefully. About the second question of centralized repositories…. I understand where you are coming from, it is more work, learning and maintenance to setup your own hosted repository. However, the way we have things now is a system that values a core set of developers, who have managed to gain access to the inner sanctum. I think that if we are going to foster a larger community of developers, we are going to need to move towards encouraging a community of developers to contribute fixes, changes, features etc. that do not depend on them first obtaining access to the ‘inner sanctum’. As the project gets bigger, and the community grows, managing an access list and keys for all the different potential developers who want to commit to the repository becomes a pain and because of this we will find ourselves moving towards only giving people access who we think should get access based on some arbitrary criteria. This makes it so new developers, before they can make a meaningful contribution, will have to satisfy this arbitrary criteria to gain access to commit their changes. Likely at this stage these developers will be frustrated and either go away, or publish their own repository somewhere to work-around this issue. Because of this, I think that we will need to accept that the distributed method of development will emerge and this is why I think embracing that early so we can shape how this will work from the beginning, rather try and retrofit things later when we realize this is happening, makes sense. I think that we want to encourage development, without throwing up roadblocks, and we can do that without it being too difficult on the existing developers. I also see value in individual developers pushing to their own repositories without fear of messing up things for others and using the main published repository as a place to focus on a particular mode of development: stabilization, integration and releases. The first problem is individual developers having to publish their own repositories, having a server that is on and learning and maintaining that published repository. I think we can resolve these issues by providing very clear documented possibilities. It actually is incredibly simple for people to use something like github or repo.or.cz and I would be happy to write documentation and show people how to do this. Riseup can also offer personal hosted repositories too, which would be maintained and available 24/7. The second problem you cite is the difficulties in keeping track of all the repositories. In other projects that use this model, this is not a problem because the way they have set things up does not require everybody to track everybody else’s repositories and when they do git was designed to do this, so it makes it really easy. Individual developers will probably only track the main repository, if they track other repositories, it would be limited. The only place where multiple repositories needs to be tracked is at the point of integration in the ‘master’ repository. When a bug has been fixed, or a feature created, the redmine ticket has the details of what branch they’ve done this work in so that the person doing the integration can pull their changes, do some code review and make a determination what branch they should be merged into and then do that. This is done using the ‘git remote’ functionality (git remote add, git remote update, etc.), which was designed specifically for this purpose. This lets someone who just wants to do a ‘drive-by’ fix, to do so without any bulky overhead, or access management by them or by us. When there is someone who is doing more than just one fix, they will typically have add their repository to a wiki page which has a list of the different developers along with their repository URIs, this is just for longer-term documentation, the actual list of repositories that are being tracked are kept in the git repository as remotes that the integration people manage. This process does require someone, or some people, to be responsible for integration. This is not unnecessary overhead, its actually a good role for someone to be responsible for because it makes a clear space for people to work towards achieving a specific goal of stabilization and versioned releases. It logically separates the haphazard nature of individual development into individual places where developers can mess up their own stuff for the purposes of developing without concern about others, from the very different process of integration and releasing. It only requires that someone has a relatively good understanding of the intended release goals and versioning, some understanding of ruby/rails, some understanding of git merging. It means being someone who sits at the stage in a ticket where it has moved from a bug with discussion and design decisions to a bug that has code that is ready for check-in. |
|
|
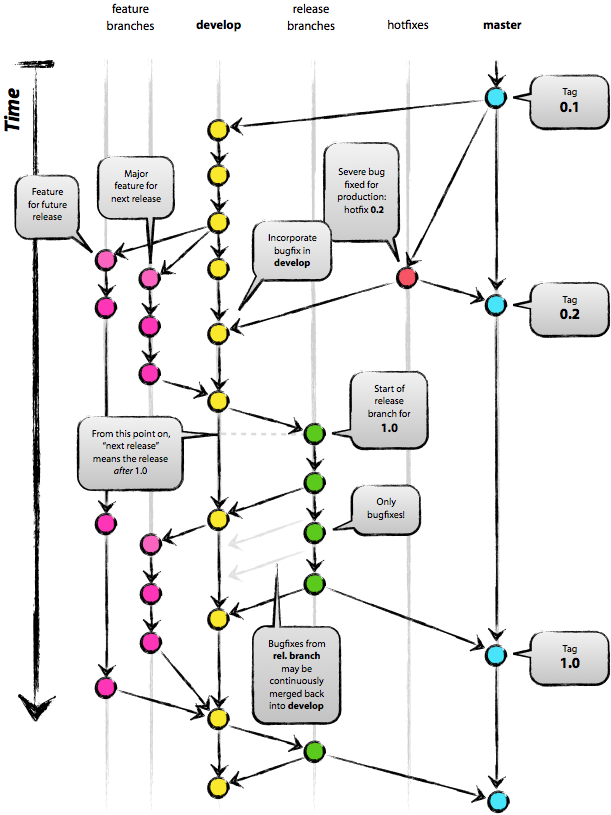
Off-topic: Which program you have used for the diagram?? |
|
|
adela, this was pulled from another website. not sure how they made it. |
|
Git Branches and Crabgrass Dev Process

This site is run by riseup.net, your friendly autonomous tech collective since 1999.

This site is powered by crabgrass, AGPL software libre for network organizing