
(this cartoon hung on the door of one of my professors in school. – taggart)
- 1 Introduction
- 2 The Problem: not enough entropy!
- 3 Applications
- 4 System Hardware Random Number Generators
- 5 Dedicated Hardware Random Number Generators
- 6 What happens without proper entropy?
Introduction¶
Many cryptographic algorithms rely critically on a source of good random numbers. These numbers are used to generate crypto keys, generate unpredicable TCP sequence numbers, and other things that help keep our servers secure.
Wikipedia has a good article on /dev/random that explains at a high level how things work.
The Linux source code drivers/char/random.c has good comments about how things work at a lower level.
Brief summary: The Linux kernel maintains a pool of entropy and to keep it “full” it gathers entropy from the environment, mainly from the input layer (like the timing between keystrokes) and from timing between interrupts of certain devices (like hard disks and network devices). Using this pool, it offers two sources of random numbers for programs to use
- /dev/random – provides numbers the kernel has confidence are truly random. If the pool of entropy does not contain sufficient randomness to attain this confidence, reads from this source will block until the kernel has generated more entropy.
- /dev/urandom – also provides numbers from the entropy pool, but if the pool is depleted will not block reads and instead continues to provide numbers that, while not a “good” as those guaranteed when using /dev/random, are still considered cryptographically secure. But theoretically they are still weaker and more susceptible to attack.
How does the Linux kernel decide to fill the pool, does it always keep it full or only when there is demand? Whenever the kernel has managed to measure some entropy (from a hard disc, network interrupt, keyboard/mouse movements etc), it mixes the bits it has collected into the pool, and increments the “total entropy” counter. The physical size of this pool is 4096 bits, so the counter tops out at 4096, although additional bits are still mixed in. When entropy is read from this pool, the counter is decremented by the appropriate amount. (Unless this counter would go negative, when reads are blocked until enough entropy has entered the pool to satisfy the request.)
Fortunately most things depend on /dev/urandom and thus won’t block when entropy hits 128 or so bits, but urandom won’t re-seed during that time, meaning that in theory, the random numbers it produces will be less strong.
FreeBSD and Linux implement /dev/random differently. In particular the Linux /dev/random implementation was done in such a way that it doesn’t try to recover from entropy pool compromise because its assumed that if you have compromised the operating system enough to be able to compromise the entropy pool, then you have plenty of other more fruitful attack vectors available to you.
Interestingly, FreeBSD symlinks /dev/urandom to /dev/random, and unlike the Linux /dev/random, the FreeBSD /dev/random doesn’t ever block. Its similar to the Linux /dev/urandom and is intended to serve as a cryptographically secure PRNG, rather than based on a pool of entropy. The algorithm that they use is based on an assumption that modern PRNGs are actually very secure if their internal state is unknown to an attacker and that this is better because entropy-estimation is a black-art and not very well understood (whereas PRNG’s are based on well-understood crypto hashes and clear algorithms). The argument is that entropy-based methods of random number generation are completely secure if they are implemented correctly (and often this is a big if), but they also can be even less secure than a well-seeded PRNG if they overestimate their entropy.
This is particularly interesting when you consider the case of a diskless system, which gets ALL of its entropy from the network, because it has none to gather from disks. This means that an attacker can have considerable amount of control over the entropy rendering the machine vulnerable to MiTM. The FreeBSD system places a lot of emphasis on managing pool compromise and recovery, resulting in a diskless FreeBSD system getting reseeded in fractions of seconds, but a Linux system being wide open for problems, that is if it doesn’t save state from the RNG on shutdown. If you save the state for seeding the random pool, then an attacker would need to have monitored the machine for it’s entire life instead, of just one reboot.
The Linux kernel, since 2.6.12, implements something called ASLR (Address Space Layout Randomization), this impacts entropy on systems. ASLR is a security technique which involves randomly setting the positions of data areas that programs use, typically the positions in memory of the executable, libraries, and stack. This stops a certain category of attacks (eg. stack smashing, return-to-libc attacks, stack shell-code injectsions, etc.) by making it more difficult for an attacker to predict where a particular process is going to put certain data segments. This is a cryptographic function, and constantly depletes entropy to be effective. As a side-note, the ASLR implementation in the Linux kernel is considered to be weak by many people, which is hardening patches, such as PAX and ExecShield provide more complete implementations.
The Problem: not enough entropy!¶
Servers that offer secure services such as https, imaps, pops, smtp with TLS, ssh, etc. and have lots of connections can often deplete the entropy pool faster than it is refilled. When this happens services using /dev/random will block and introduce delays and services using /dev/urandom will continue to provide numbers, but that are theoretically less secure and potentially at a slower rate.
In virtual environments, entropy can quickly become a problem not only because you may have multiple machines virtualized on one host with a limited amount of entropy available, but also because virtualized hosts are often unable to gather their own entropy effectively, as they have no real “hardware” from which to measure it.
The built-in pool of random data on Linux (/dev/random) is of fixed size (just 4kB) which is limited. If an application tries to read from the pool, and there is not enough data to satisfy its request, the application is blocked until enough entropy has been collected to fill the pool to the point of being able to satisfy the request, leading to delays in the delivery of services. Its possible to use a non-blocking random source (/dev/urandom), but this is considered a poor source of randomness and should not be relied on for strong cryptographic operations.
Examples¶
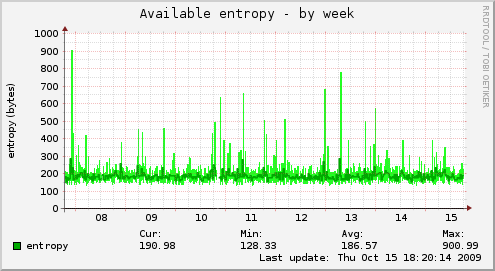
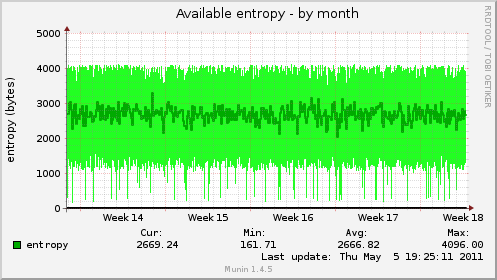
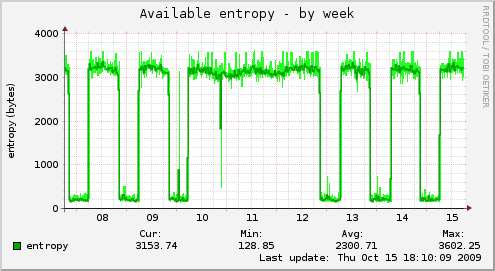
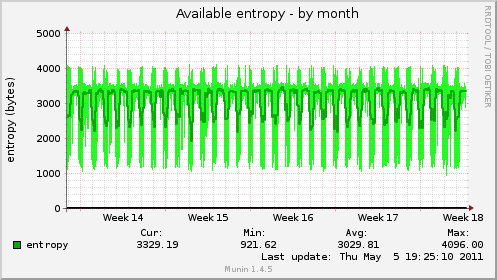
Here are some examples of types of riseup machines and their entropy graphs when the entropy was problematic (in October 2009), and then the same machine’s graphs after the entropy key was added to the system. There is a pretty clear difference in available entropy!
Front End Web Server (aka FEWS)¶
These machines run webmail frontends via https, perdition imaps and pops proxies, SMTP+TLS, and use a VPN to talk to other riseup machines.
Before
After
Back End Mail Server (aka BEMS)¶
These machines run imaps, pops, and use a VPN to talk to other riseup machines.
Before
After
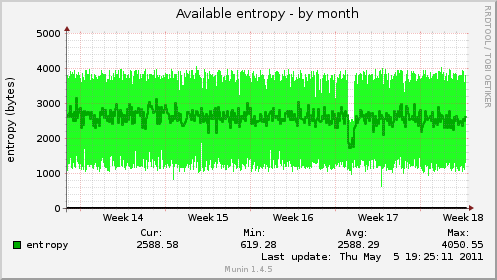
Listserver¶
This machine uses SMTP+TLS (in and outbound) and https (sympa web interface).
Before
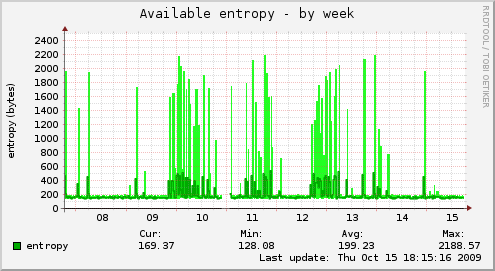
After
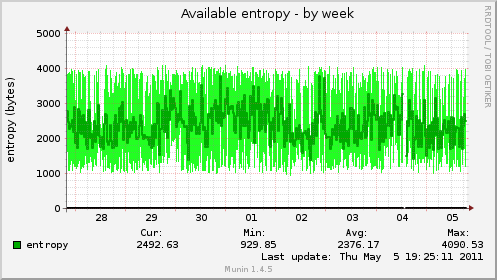
MX servers¶
These machines use SMTP+TLS (in and outbound).
Before
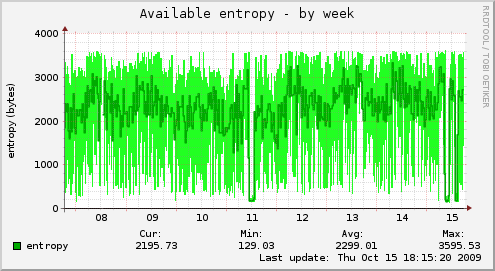
After
Applications¶
There are many applications that let you configure the locations of random sources and random seeds. All of these individual configurations are designed to either allow you to configure a non-blocking random source (eg. /dev/urandom); set a file where a persistent seed can be read from to initialize an internal PRNG; or to set the application to read directly from a hardware random number generator, or daemon such as EGD. Many applications can update straight from from the entropy gathering daemon (EGD), but if EGD is keeping the kernel pool topped off then there is no point changing it from the default.
OpenSSL:: maintains it’s own pool of entropy and PRNG: /etc/ssh/openssl.cnf allows you to configure
RANDFILE = /dev/urandomOpenSSH:: It prefers to use /dev/random, if you have it, if not it has a built-in pRNG, which is slow.
Postfix:: maintains it’s own pool of entropy and has a PRNG that it seeds from other sources, by default
tls_random_source = dev:/dev/urandomMore on postfix’s entropy setting here.
Apache:: allows you to set the following:
SSLRandomSeed startup file:/dev/urandom 512SSLRandomSeed connect file:/dev/urandom 512php:: allows you to set
session.entropy_file = /dev/urandom in php.confSystem Hardware Random Number Generators¶
“HAVGED is a userspace entropy daemon which is not dependent upon the standard mechanisms for harvesting randomness for the system entropy pool. This is important in systems with high entropy needs or limited user interaction (e.g. headless servers).”
apt-get install havegedDedicated Hardware Random Number Generators¶
Audio device entropy¶
There is the audio entropy daemon which feeds /dev/random with entropy data read from an audio device.
Entropy Key¶
The Entropy Key is a small USB key/stick device that provides high-quality entropy to a system, keeping /dev/random topped up with strong entropic random data, helping to keep it from blocking applications that are drawing from the device. The key is designed to spit out at least 30,000 bits per second of entropy. This is more than enough to keep Linux’s 4096 bit pool full, and refill it promptly, as well as being enough to do this for several machines if done over a network. The Entropy Key feeds a daemon, which throws that entropy into the pool, and keeping it filled. It also can provide that entropy to other daemons over the network. The data is sent via a packetized, plain ASCII-text, encrypted and authenticated serial protocol to the daemon interface (this means you can’t just dd from the device). It is important that this is done this way because USB is a broadcast bus, and a lot (timing at least) can be sniffed by a small dongle.
The Entropy Key is a USB2.0 device, but only at the protocol layer. It is actually only a 12Mbps device which is the max speed of USB1.1. It was designed this way to keep hubs from dropping to Low Speed when you plug in the key. So you can actually use this device on a USB1.1 system without problems.
The EGD mode of the daemon allows you to share entropy among virtual machines running on the host. The downside of this system is that the on-wire protocol for EGD has no security. It is not very useful for running over physical networks. If you want to share entropy across a physical network, then using software like Entropy Broker by Folkert Van Heusden may help. Folkert recently added EGD client support to Entropy Broker so it could retrieve entropy directly from the Entropy Key daemon, rather than going via the /dev/random pool.
Entropy Key Questions¶
Q. How can we be sure that the Entropy Key that was plugged into a host system has not been physically replaced by an adversary?
A. “The Entropy Key authenticates all packets it sends using a packet-MAC mechanism where the MAC includes the session key generated during communication with the host. The session key is routinely regenerated using a shared secret, unique to each Entropy Key, which can be changed at will by the owner of the Entropy Key.” There is a device-specific Master Key that is coded into each individual Entropy key. This is used to setup this initial Long Term key which is then used to generate Session keys. You can change these at any time, if you have access to the Master Key. If you do not, then any changes to these, or to the hardware will cause the daemon to not function properly.
Q. How can we prove that the data we are getting is truly random? Being able to verify the randomness of the data would is important!
A. You can run the daemon in a mode where it will simply dump all the random data collected from the Entropy Key to a file, at which point you can run tools such as ent, rngtest, diehard, etc over the data. The Entropy Key does internally do randomness tests, specified by FIPS 140-2 continually. If failure rates rise higher than could be statistically expected, then the Entropy Key automatically stops and informs the host computer.
Q. How can we be sure that the Entropy Key was not manufactured with some kind of backdoor, or deliberately hidden weakness that generates a pattern of random data that is not perceivable?
A. Well, we can’t. We also can’t be sure that the CPU and other chipset manufacturers aren’t doing this either. Given that the Entropy Key is only designed to “top up” your existing pool, data collected from the device is mixed with entropy gathered by other sources by your computer. If some intelligence agency were able to simply calculate what bits you were delivered, it would have been mixed with bits they can’t know. While it certainly would help them calculate the data used, it would still be far from easy.
Q. How open is this device anyways?
A. The source to the firmware is not currently available from Simtec. The keys are epoxied and one-time programmable, which would make it impossible to verify the source with the firmware if we did have it. Simtec is willing to provide keys with JTAG programming headers with no firmware, information about how to access the generators and a gcc-based toolchain so one could write their own firmware. However, the userland daemon is under the MIT licence and open, and the protocol is fully documented and public.
Accepting a closed solution because everything else is not yet free/open is not a particularly compelling rationale. This is one of the key reasons why we have open source, this is the reason why there is coreboot, and the reason why we want an open phone. Sure the CPU and the chipset manufacturers are not open, so we cannot inspect them to determine for ourselves that they are 100% “clean”, but that in itself is not a reason why we should accept closed hardware (or software). We dont trust the CPU manufacturers, and recognize these as weak points that we currently dont have any options on right now.
Q. The kernel pool is being fed by this external device, and that means there is mixture from the kernel… but at what point does such a mixture not matter? Lets say the key is generating 99.99999% of the entropy of the system, and it has been tampered with to provide a secret known pattern, one designed well enough to pass the randomness tests. The kernel injects a fairly trivial amount of “true” random data from environmental noise, hard disks, mouse movements, etc, say 00.00001% of the total. Is that amount sufficient to disrupt the theoretically known pattern hidden in the entropy beyond recognition? The 30,000 bits per second that the Entropy key sends is a lot of bits, and according to Simtec, that it is plenty enough to keep the pool full, and refill it immediately. But does that mean that the kernel’s pool is so flooded by this external pool, that the bits that the kernel mixes in from its environmental sources are totally displaced by the external pool so much that it is indistinguishable from the external pool?
A. Lets say an attacker is able to provide a pattern matrix that they spit out of the ‘entropy’ generator, this data would not pass FIPS-140 because its predictability would be too obvious. So what they do is pass it through their hash function to turn it into unintelligible data before they spit it out of the device, that data passes the FIPS-140 test, and they know what it is, and that is fed into the random pool. Now this data that comes out of the device gets sent to /dev/random, which passes it through drivers/char/random.c, then that gets passed through a SHA hash function to transform that data before it is fed into the kernel entropy pool. However, if that data is mixed with other random data from the system, are we comfortable accepting that the SHA of that mixture is totally unpredictable? If an attacker knows the input to the hash, knows the hash function and thus could calculate what the hash output would be, they won’t know the beginning pool state, and so cannot know how their input affects it when it goes through the mixing method. So all they have done is adding entropy. The comments in random.c detail this:
* The fact that an intelligent attacker can construct inputs that
* will produce controlled alterations to the pool's state is not
* important because we don't consider such inputs to contribute any
* randomness. The only property we need with respect to them is that
* the attacker can't increase his/her knowledge of the pool's state.
* Since all additions are reversible (knowing the final state and the
* input, you can reconstruct the initial state), if an attacker has
* any uncertainty about the initial state, he/she can only shuffle
* that uncertainty about, but never cause any collisions (which would
* decrease the uncertainty).
Is there a bias in the output that is being removed? Typically transistors in avalanche mode are difficult to detect when they fail, and have a bias in their output.
What happens without proper entropy?¶
One example of a system without proper entropy was Debian’s mistaken release of OpenSSL with a poorly-seeded random number generator
A good article on what happens if your RNG sucks
Other examples?
|
Info about HAVEGED at pthree.org/2012/09/14/haveged-a-true-ra... |
|

